TL-B 언어
TL-B(타입 언어 - 바이너리)는 타입 시스템, 생성자 및 기존 함수를 설명하는 역할을 합니다. 예를 들어,
에서 TL-B 스키마를 사용하여 TON 블록체인과 관련된 바이너리 구조를 구축할 수 있습니다. 특수 TL-B 파서는 스키마를 읽어
바이너리 데이터를 다른 객체로 역직렬화할 수 있습니다. TL-B는 Cell 객체에 대한 데이터 스키마를 설명합니다. '셀'에 익숙하지 않으시다면
셀과 셀의 가방(BOC) 글을 읽어보시기 바랍니다.
개요
우리는 모든 TL-B 구조체 집합을 TL-B 문서라고 부릅니다. TL-B 문서는 일반적으로 타입 선언(
즉, 생성자)과 함수 결합자로 구성됩니다. 각 결합자의 선언은 세미콜론(;)으로 끝납니다.
다음은 가능한 결합기 선언의 예입니다:
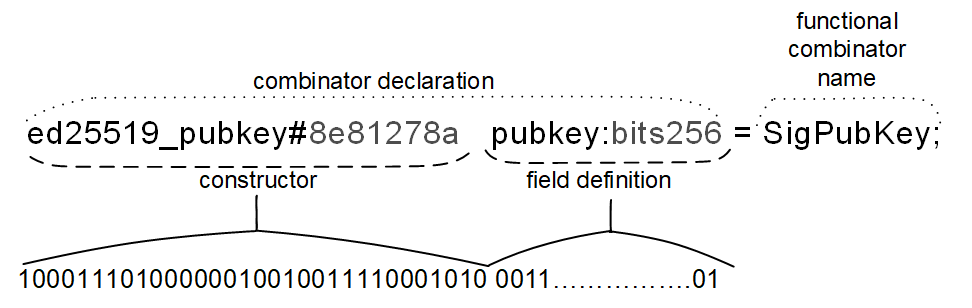
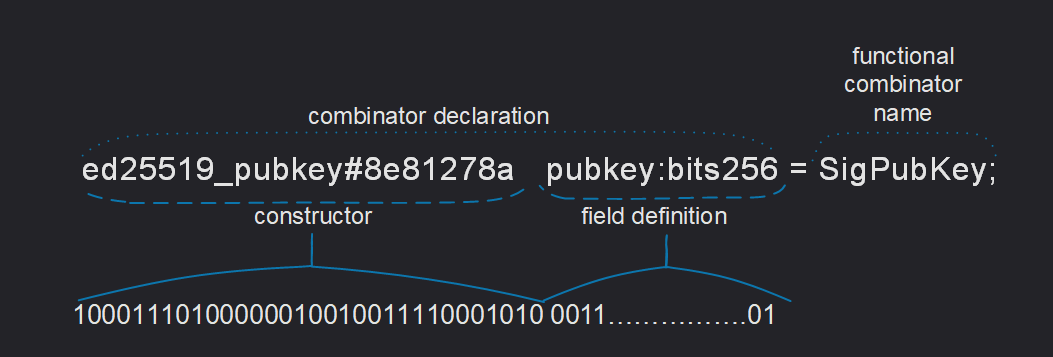
생성자
각 방정식의 왼쪽에는 오른쪽에 표시된 유형의 값을 정의하거나 직렬화하는 방법이 설명되어 있습니다. 이러한 설명은 생성자 이름으로 시작됩니다.

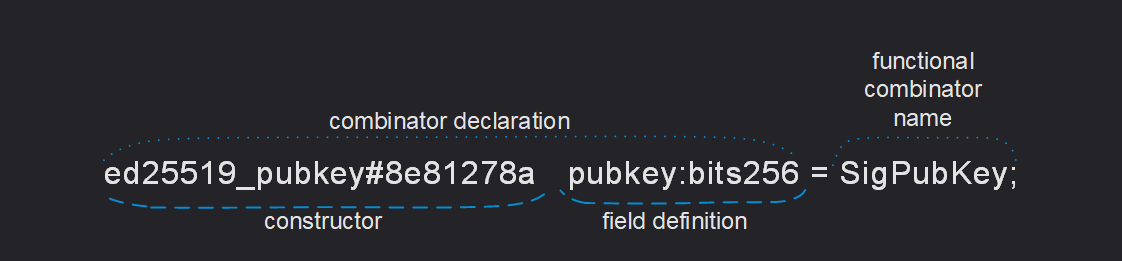
생성자는 직렬화 시 상태를 포함해 결합자의 유형을 지정하는 데 사용됩니다. 예를 들어, TON에서 스마트 컨트랙트에 대한 쿼리에서 op(연산 코드)를 지정하고자 할 때
생성자를 사용할 수도 있습니다.
// ....
transfer#5fcc3d14 <...> = InternalMsgBody;
// ....
- 생성자 이름:
전송 - 생성자 접두사 코드:
#5fcc3d14
모든 생성자 이름 바로 뒤에는 #_ 또는 $10과 같은 선택적 생성자 태그가 있는데,
이 태그는 해당 생성자를 인코딩(직렬화)하는 데 사용되는 비트스트링을 설명합니다.
message#3f5476ca value:# = CoolMessage;
bool_true$0 = Bool;
bool_false$1 = Bool;
각 수식의 왼쪽에는
오른쪽에 표시된 유형의 값을 정의하거나 직렬화하는 방법이 설명되어 있습니다. 이러한 설명은 message 또는 bool_true와 같은 생성자 이름으로 시작하여
바로 뒤에 #3f5476ca 또는 $0와 같이 해당 생성자를 인코딩(
직렬화)
하는 데 사용되는 비트를 설명하는 선택적 생성자 태그가 이어집니다.
| 생성자 | 직렬화 |
|---|---|
some#3f5476ca | 32비트 16진수 값에서 직렬화하기 |
some#5fe | 12비트 16진수 값에서 직렬화하기 |
some$0101 | 0101` 원시 비트 직렬화 |
일부또는일부#` | 직렬화 RCRC32(방정식) \| 0x80000000 |
일부#또는일부$또는_` | 아무것도 직렬화하지 않음 |
생성자 이름(이 예제에서는 일부)은 코드 생성기에서 변수로 사용됩니다. 예를 들어
bool_true$1 = Bool;
bool_false$0 = Bool;
유형 Bool에는 두 개의 태그 0과 1이 있습니다. 코드젠 의사 코드는 다음과 같습니다:
class Bool:
tags = [1, 0]
tags_names = ['bool_true', 'bool_false']
현재 생성자의 이름을 정의하지 않으려면 _를 전달하면 됩니다(예: _ a:(## 32) = 32Int;).
생성자 태그는 이진(달러 기호 뒤) 또는 16진수 표기법(해시 기호 뒤)으로 지정할 수 있습니다.
태그가
명시적으로 제공되지 않은 경우, TL-B 구문 분석기는 이 생성자를 특정 방식으로 정의하는 | 0x80000000이 포함된 '방정식'의 텍스트를 CRC32 알고리즘
으로 해싱하여 기본 32비트 생성자 태그를 계산해야 합니다. 따라서 빈 태그
는 #_ 또는 $_로 명시적으로 제공해야 합니다.
이 태그는 역직렬화 프로세스에서 현재 비트스트링의 유형을 추측하는 데 사용됩니다. 예를 들어 1비트 비트 문자열 0이 있는데,
이 비트 문자열을 Bool 유형으로 파싱하라고 TLB에 지시하면 Bool.bool_false로 파싱합니다.
좀 더 복잡한 예가 있다고 가정해 보겠습니다:
tag_a$10 val:(## 32) = A;
tag_b$00 val(## 64) = A;
TLB 유형 A에서 1000000000000000000000000000000001(0과 1 32개)를 파싱하면 먼저 태그를 정의하기 위해
두 비트를 가져와야 합니다. 이 예제에서 10은 두 개의 첫 번째 비트이며 tag_a를 나타냅니다. 이제 다음 32개의
비트가 val 변수이며 이 예제에서는 1이라는 것을 알 수 있습니다. 일부 "파싱된" 의사 코드 변수는 다음과 같이 보일 수 있습니다:
A.tag = 'tag_a'
A.tag_bits = '10'
A.val = 1
모든 생성자 이름은 고유해야 하며 동일한 유형의 생성자 태그는 접두사 코드를 구성해야 합니다(그렇지 않으면 역직렬화는 고유하지 않습니다). 즉, 동일한 유형의 다른 태그의 접두사가 될 수 없는 태그는 없습니다.
한 유형당 최대 생성자 수: 64태그의 최대 비트:63`
example_a$10 = A;
example_b$01 = A;
example_c$11 = A;
example_d$00 = A;
코드젠 의사 코드는 다음과 같이 보일 수 있습니다:
class A:
tags = [2, 1, 3, 0]
tags_names = ['example_a', 'example_b', 'example_c', 'example_d']
example_a#0 = A;
example_b#1 = A;
example_c#f = A;
코드젠 의사 코드는 다음과 같이 보일 수 있습니다:
class A:
tags = [0, 1, 15]
tags_names = ['example_a', 'example_b', 'example_c']
헥스` 태그를 사용하는 경우 각 16진수 기호에 대해 4비트로 직렬화된다는 점에 유의하세요. 최대 값은 63비트 부호 없는 정수입니다. 이는 다음을 의미합니다:
a#32 a:(## 32) = AMultiTagInt;
b#1111 a:(## 32) = AMultiTagInt;
c#5FE a:(## 32) = AMultiTagInt;
d#3F5476CA a:(## 32) = AMultiTagInt;
| 생성자 | 직렬화 |
|---|---|
a#32 | 8비트 16진수 값에서 직렬화하기 |
b#1111 | 16비트 16진수 값에서 직렬화 |
c#5FE | 12비트 16진수 값에서 직렬화하기 |
d#3F5476CA | 32비트 16진수 값에서 직렬화하기 |
또한 16진수 값은 대문자와 소문자 모두 허용됩니다.
16진수 태그에 대해 자세히 알아보기
일반적인 16진수 태그 정의 외에도 16진수 뒤에 밑줄 문자를 추가할 수 있습니다. 이는 태그가 최하위 비트를 제외한 지정된 16진수와 같음을 의미합니다. 예를 들어 다음과 같은 방식이 있습니다:
vm_stk_int#0201_ value:int257 = VmStackValue;
그리고 이 태그는 실제로 0x0201과 같지 않습니다. 이를 계산하려면 0x0201의 이진 표현에서 LSb를 제거해야 합니다:
0000001000000001 -> 000000100000000
따라서 태그는 15비트 이진수 0b000000100000000에 해당합니다.
필드 정의
생성자와 그 선택적 태그 뒤에는 필드 정의가 이어집니다. 각 필드 정의는 형식이며, 여기서 ident는 필드 이름( 익명 필드의 경우 밑줄로 대체됨)이 포함된 식별자이고 type-expr은 필드의 유형입니다. 여기에 제공되는 유형은 유형 표현식으로, 단순 유형, 적절한 매개변수가 있는 매개변수화된 유형 또는 복잡한 표현식을 포함할 수 있습니다.
유형에 정의된 모든 필드는 셀(`1023` 비트 및 `4` 참조)보다 크지 않아야 합니다.단순 유형
_ a:# = Type;- 여기서Type.a는 32비트 정수입니다._ a:(## 64) = Type;- 여기서Type.a는 64비트 정수입니다._ a:소유자 = NFT;-NFT.a는소유자유형입니다.- a:^Owner = NFT;
- 여기서NFT.a는소유자에 대한 셀 참조 유형으로소유자`가 다음 셀 참조에 저장된다는 의미입니다.
익명 필드
_ _:# = A;- 첫 번째 필드는 익명 32비트 정수입니다.
참조가 있는 셀 확장
_ a:(##32) ^[ b:(##32) c:(## 32) d:(## 32)] = A;
- 어떤 이유로 일부 필드를 다른
셀로 분리하려는 경우
^[ ... ]구문을 사용할 수 있습니다. 이 예제에서A.a/A.b/A.c/A.d는 32비트 부호 없는 정수이지만A.a는 첫 번째 셀에 저장되고 및A.b/A.c/A.d는 다음 셀에 저장됩니다(1 참조).
_ ^[ a:(## 32) ^[ b:(## 32) ^[ c:(## 32) ] ] ] = A;
- 참조 연쇄도 허용됩니다. 이 예제에서는 각
변수(
a,b,c)가 별도의 셀에 저장됩니다.
매개변수화된 유형
IntWithObj` 타입이 있다고 가정해봅시다:
_ {X:Type} a:# b:X = IntWithObj X;
이제 다른 유형에서도 사용할 수 있습니다:
_ a:(IntWithObj uint32) = IntWithUint32;
복잡한 표현식
조건부 필드(
Nat에만 해당) (E?T는 필드 유형이T인 경우 표현식E가 참인 경우를 의미함)._ a:(## 1) b:a?(## 32) = Example;예제
에서a가1인 경우에만 변수b`가 직렬화됩니다.튜플 생성을 위한 곱하기 표현식(
x * T는T유형의 길이x의 튜플을 생성한다는 의미):a$_ a:(## 32) = A;
b$_ b:(2 * A) = B;_ (## 1) = Bit;
_ 2bits:(2 * Bit) = 2Bits;비트 선택 (
Nat에만 해당) (E . B는NatE의 비트B를 취함을 의미)_ a:(## 2) b:(a . 1)?(## 32) = Example;예제
에서 두 번째 비트a가1인 경우에만 변수b`가 직렬화됩니다.다른
Nat연산자도 허용됩니다(허용되는 제한 사항참조).
참고: 여러 개의 복잡한 표현식을 결합할 수 있습니다:
_ a:(## 1) b:(## 1) c:(## 2) d:(a?(b?((c . 1)?(## 64)))) = A;
기본 제공 유형
#-Nat32비트 부호 없는 정수- x
비트가 있는## x-Nat` - '#\< x
- 'Nat보다 작은x비트 부호 없는 정수, 최대 31비트까지lenBits(x - 1)비트로 저장됩니다. - '#\<= x
- 'x'보다 작거나 같은Nat비트 부호 없는 정수, 최대 32비트까지lenBits(x)` 비트로 저장됩니다. - '아무
/ '셀- 나머지 셀 비트 및 참조 - In` - 257비트
UInt- 256비트- 비트` - 1023비트
- uint1
-uint256` - 1 - 256비트 - int1
-int257` - 1 - 257비트 - bits1
-bits1023` - 1 - 1023비트 - uint X
/int X/bits X-uintX와 동일하지만 이 유형에서 매개변수화된X`를 사용할 수 있습니다.
제약 조건
_ flags:(## 10) { flags <= 100 } = Flag;
제약 조건에 허용되는 Nat 필드. 이 예제에서 { flags <= 100 } 제약 조건은 flags 변수가
또는
보다 작거나 100과 같음을 의미합니다.
허용된 제한 사항: e-|e = e-|e \<= e-|e \< E|E >= e-|e > e-|e + e-|e * e-|e ? E`
암시적 필드
일부 필드는 암시적일 수 있습니다.
이러한 필드의 정의는 중괄호({, })로 둘러싸여 있는데, 이는 해당 필드가 실제로 직렬화에는 없지만 다른 데이터(일반적으로 직렬화되는 유형의 매개 변수)에서 해당 값을
추론해야 함을 나타냅니다. 예시:
nothing$0 {X:Type} = Maybe X;
just$1 {X:Type} value:X = Maybe X;
_ {x:#} a:(## 32) { ~x = a + 1 } = Example;
매개변수화된 유형
변수, 즉 이전에
정의된 #(자연수) 또는 Type(유형) 유형의 필드(식별자)는 매개변수화된
유형의 파라미터로 사용될 수 있습니다. 직렬화 프로세스는 각 필드를 유형에 따라 재귀적으로 직렬화하며
값의 직렬화는 궁극적으로 생성자(즉, 생성자 태그)와
필드 값을 나타내는 비트의 연결로 구성됩니다.
자연수(Nat)
_ {x:#} my_val:(## x) = A x;
A가 x Nat에 의해 매개변수화됨을 의미합니다. 역직렬화 프로세스에서는 x` 비트 부호 없는 정수를 가져옵니다:
_ value:(A 32) = My32UintValue;
My32UintValue 타입의 역직렬화 프로세스보다 32비트 부호 없는 정수를 가져오는 것을 의미합니다(32파라미터가A` 타입이기 때문에).
유형
_ {X:Type} my_val:(## 32) next_val:X = A X;
A가 X타입으로 매개변수화되었음을 의미합니다. 역직렬화 프로세스에서는 32비트 부호 없는 정수를 가져오고
보다X` 유형의
비트 및 참조를 파싱합니다.
이러한 매개변수화된 유형의 사용 예는 다음과 같습니다:
_ bit:(## 1) = Bit;
_ 32intwbit:(A Bit) = 32IntWithBit;
이 예제에서는 Bit 유형을 A에 매개변수로 전달합니다.
유형을 정의하고 싶지 않지만 이 체계로 역직렬화하려면 Any 단어를 사용하면 됩니다:
_ my_val:(A Any) = Example;
예제유형을 역직렬화하면 32비트 정수를 가져온 다음 나머지 셀(비트 및 참조)을my_val`로 가져온다는 의미입니다.
여러 매개 변수가 있는 복잡한 유형을 만들 수 있습니다:
_ {X:Type} {Y:Type} my_val:(## 32) next_val:X next_next_val:Y = A X Y;
_ bit:(## 1) = Bit;
_ a_with_two_bits:(A Bit Bit) = AWithTwoBits;
또한 이러한 매개변수화된 유형에 부분 적용을 사용할 수도 있습니다:
_ {X:Type} {Y:Type} v1:X v2:Y = A X Y;
_ bit:(## 1) = Bit;
_ {X:Type} bits:(A Bit X) = BitA X;
또는 매개변수화된 유형 자체도 마찬가지입니다:
_ {X:Type} v1:X = A X;
_ {X:Type} d1:X = B X;
_ {X:Type} bits:(A (B X)) = AB X;
매개변수화된 유형에 대한 NAT 필드 사용법
이전에 정의한 필드를 매개변수처럼 유형에 사용할 수 있습니다. 직렬화는 런타임에 결정됩니다.
간단한 예입니다:
_ a:(## 8) b:(## a) = A;
이는 b 필드의 크기를 a 필드 안에 저장한다는 의미입니다. 따라서 A 타입을 직렬화하려면 a 필드에 8개의
비트 부호 없는 정수를 로드한 다음 이 숫자를 사용하여 b 필드의 크기를 결정해야 합니다.
이 전략은 매개변수화된 유형에도 적용됩니다:
_ {input:#} c:(## input) = B input;
_ a:(## 8) c_in_b:(B a) = A;
매개변수화된 유형의 표현식
_ {x:#} value:(## x) = Example (x * 2);
_ _:(Example 4) = 2BitInteger;
이 예제에서 Example.value 유형은 런타임에 결정됩니다.
2비트 정수정의에서예제 4유형을 값으로 설정합니다. 이 유형을 결정하기 위해예제 (x * 2)
정의를 사용하고 공식 (y = 2, z = 4)에 따라 x`를 계산합니다:
static inline bool mul_r1(int& x, int y, int z) {
return y && !(z % y) && (x = z / y) >= 0;
}
추가 연산자를 사용할 수도 있습니다:
_ {x:#} value:(## x) = ExampleSum (x + 3);
_ _:(ExampleSum 4) = 1BitInteger;
1비트 정수정의에서ExampleSum 4유형으로 값을 설정합니다. 이 유형을 결정하기 위해ExampleSum (x + 3)
정의를 사용하고 공식(y = 3, z = 4)에 따라 x`를 계산합니다:
static inline bool add_r1(int& x, int y, int z) {
return z >= y && (x = z - y) >= 0;
}
음수 연산자(~)
일부 '변수'(즉, 이미 정의된 필드)는 앞에 물결표(~)가 붙습니다. 이는
변수의 발생이 기본 동작과 반대되는 방식으로 사용됨을 나타냅니다. 방정식의 왼쪽에서
은 변수가 이전에
계산된 값을 대체하는 대신 이 발생을 기반으로 추론(계산)된다는 것을 의미하고, 오른쪽에서는 반대로 변수가
직렬화되는 유형에서 추론되지 않고 역직렬화 프로세스 중에 계산된다는 것을 의미합니다. 즉, 물결표는
'입력 인자'를 '출력 인자'로 변환하거나 그 반대로 변환합니다.
네거티브 연산자의 간단한 예는 다른 변수를 기반으로 새 변수를 정의하는 것입니다:
_ a:(## 32) { b:# } { ~b = a + 100 } = B_Calc_Example;
정의 후 새 변수를 사용하여 Nat 유형에 전달할 수 있습니다:
_ a:(## 8) { b:# } { ~b = a + 10 }
example_dynamic_var:(## b) = B_Calc_Example;
예제_dynamic_var의 크기는 a변수를 로드할 때 런타임에 계산되며, 이 값을example_dynamic_var` 크기 결정에 사용합니다.
또는 다른 유형으로 전환할 수도 있습니다:
_ {X:Type} a:^X = PutToRef X;
_ a:(## 32) { b:# } { ~b = a + 100 }
my_ref: (PutToRef b) = B_Calc_Example;
또한 더하기 또는 곱하기 복잡한 표현식에서 음수 연산자를 사용하여 변수를 정의할 수 있습니다:
_ a:(## 32) { b:# } { ~b + 100 = a } = B_Calc_Example;
_ a:(## 32) { b:# } { ~b * 5 = a } = B_Calc_Example;
유형 정의에서 연산자(~) 무효화
_ {m:#} n:(## m) = Define ~n m;
_ {n_from_define:#} defined_val:(Define ~n_from_define 8) real_value:(## n_from_define) = Example;
m을 취하고 m비트 부호 없는 정수에서 로드하여n을 계산하는 Define ~n m` 클래스가 있다고 가정합니다.
예제유형에서는Define유형으로 계산된 변수를n_from_define에 저장하고, Define ~n_from_define 8로 Define유형을 적용하므로8비트
부호 없는 정수라는 것을 알 수 있습니다. 이제 다른 타입에서n_from_define` 변수
를 사용하여 직렬화 프로세스를 결정할 수 있습니다.
이 기술은 더 복잡한 유형 정의(예: 유니온, 해시맵)로 이어집니다.
unary_zero$0 = Unary ~0;
unary_succ$1 {n:#} x:(Unary ~n) = Unary ~(n + 1);
_ u:(Unary Any) = UnaryChain;
이 예제는 TL-B 타입
문서에 좋은 설명이 있습니다. 여기서 주요 아이디어는 UnaryChain이 unary_zero$0에 도달할 때까지 재귀적으로 역직렬화한다는 것입니다(unary_zero$0 = Unary ~0; 정의로 인해 Unary X 타입의 마지막 요소를
알고 있고, X는 런타임에
Unary ~(n + 1) 정의로 인해 계산되기 때문입니다).
참고: x:(Unary ~n)은 유나리 클래스의 직렬화 과정에서 n이 정의된다는 의미입니다.
특수 유형
현재 TVM은 셀 유형을 허용합니다:
- 보통
- PrunnedBranch
- 라이브러리
- 머클프루프
- 머클업데이트
기본적으로 모든 셀은 일반입니다. 그리고 tlb에 설명된 모든 셀은 일반입니다.
생성자에서 특수 유형을 로드하려면 생성자 앞에 !를 추가해야 합니다.
예시:
!merkle_update#02 {X:Type} old_hash:bits256 new_hash:bits256
old:^X new:^X = MERKLE_UPDATE X;
!merkle_proof#03 {X:Type} virtual_hash:bits256 depth:uint16 virtual_root:^X = MERKLE_PROOF X;
이 기술을 사용하면 구조를 인쇄할 때 코드젠 코드에서 '특수' 셀을 표시할 수 있으며, 특수 셀이 있는 구조의 유효성을 올바르게 확인할 수 있습니다.
생성자 고유성 태그 검사 없이 한 유형에 대해 여러 인스턴스 생성
유형 매개변수에만 따라 한 유형의 인스턴스를 여러 개 생성할 수 있습니다. 이러한 정의 방식에서는 생성자 태그 고유성 검사가 적용되지 않습니다.
예시:
_ = A 1;
a$01 = A 2;
b$01 = A 3;
_ test:# = A 4;
역직렬화를 위한 실제 태그가 A 유형 매개변수에 의해 결정됨을 의미합니다:
# class for type `A`
class A(TLBComplex):
class Tag(Enum):
a = 0
b = 1
cons1 = 2
cons4 = 3
cons_len = [2, 2, 0, 0]
cons_tag = [1, 1, 0, 0]
m_: int = None
def __init__(self, m: int):
self.m_ = m
def get_tag(self, cs: CellSlice) -> Optional["A.Tag"]:
tag = self.m_
if tag == 1:
return A.Tag.cons1
if tag == 2:
return A.Tag.a
if tag == 3:
return A.Tag.b
if tag == 4:
return A.Tag.cons4
return None
여러 매개변수에서도 동일하게 작동합니다:
_ = A 1 1;
a$01 = A 2 1;
b$01 = A 3 3;
_ test:# = A 4 2;
매개변수화된 유형 정의를 추가할 때 사전 정의된 유형 정의(예시에서는 a
및 b)와
매개변수화된 유형 정의(예시에서는 c) 사이의 태그는 고유해야 한다는 점에 유의하시기 바랍니다:
유효하지 않은 예:
a$01 = A 2 1;
b$11 = A 3 3;
c$11 {X:#} {Y:#} = A X Y;
유효한 예:
a$01 = A 2 1;
b$01 = A 3 3;
c$11 {X:#} {Y:#} = A X Y;
댓글
주석은 C++에서와 동일합니다.
/*
This is
a comment
*/
// This is one line comment
IDE 지원
intellij-ton](https://github.com/andreypfau/intellij-ton) 플러그인은 Fift, FunC 및 TL-B도 지원합니다.\ TL-B 문법은 의 TlbParser.bnf 파일에 설명되어 있습니다.
유용한 소스
Disintar](https://dton.io/) 팀에서 제공한 문서입니다.